Digital Retail Algorithms: The Gateways to Modern Consumers
Over the last decade, we have seen the content recommendation algorithms of Twitter and Facebook completely transform the news content we consume. A similar transformation is actively unfolding in the retail sector as the product sorting, ranking, recommendation and buying algorithms of Amazon, Walmart.com and Instacart increasingly dictate the products we discover and ultimately purchase. These digital retail platforms are now the primary gateways to consumers and, in response, brands must carefully monitor associated data patterns in order to breakthrough and reach their consumers. Investment in statistical anomaly detection and responsive workflows are quickly becoming table stakes for digital retail success.
In 2021, eCommerce is going to be a $1T business in the United States and over half of purchases will be on Amazon.com, where more than 90% of purchases preceded by a search event. Roughly 80% of those search events are brand agnostic (meaning there is not a trademarked brand term in the user-entered text string) and more than 70% of the users who perform a search never scroll beyond the first page of search results they are presented. Let that sink in for a moment. If you are brand, the Amazon search ranking algorithm (A9) is now the primary gateway to the US consumer.
And it’s not just Amazon. The same dynamics are at play across all the platforms that are creating deep links between physical and digital retail. Since these types of algorithms are ultimately the arbiters of how often your products are viewed and, by association, purchased, it is important to understand what they are attempting to optimize. For organic search results, fortunately that answer is fairly simple. These platforms are fundamentally buying platforms; they simply wish to show the products that have the highest probability of being purchased. As such, their ranking algorithm essentially focuses on two things: relevance and performance.
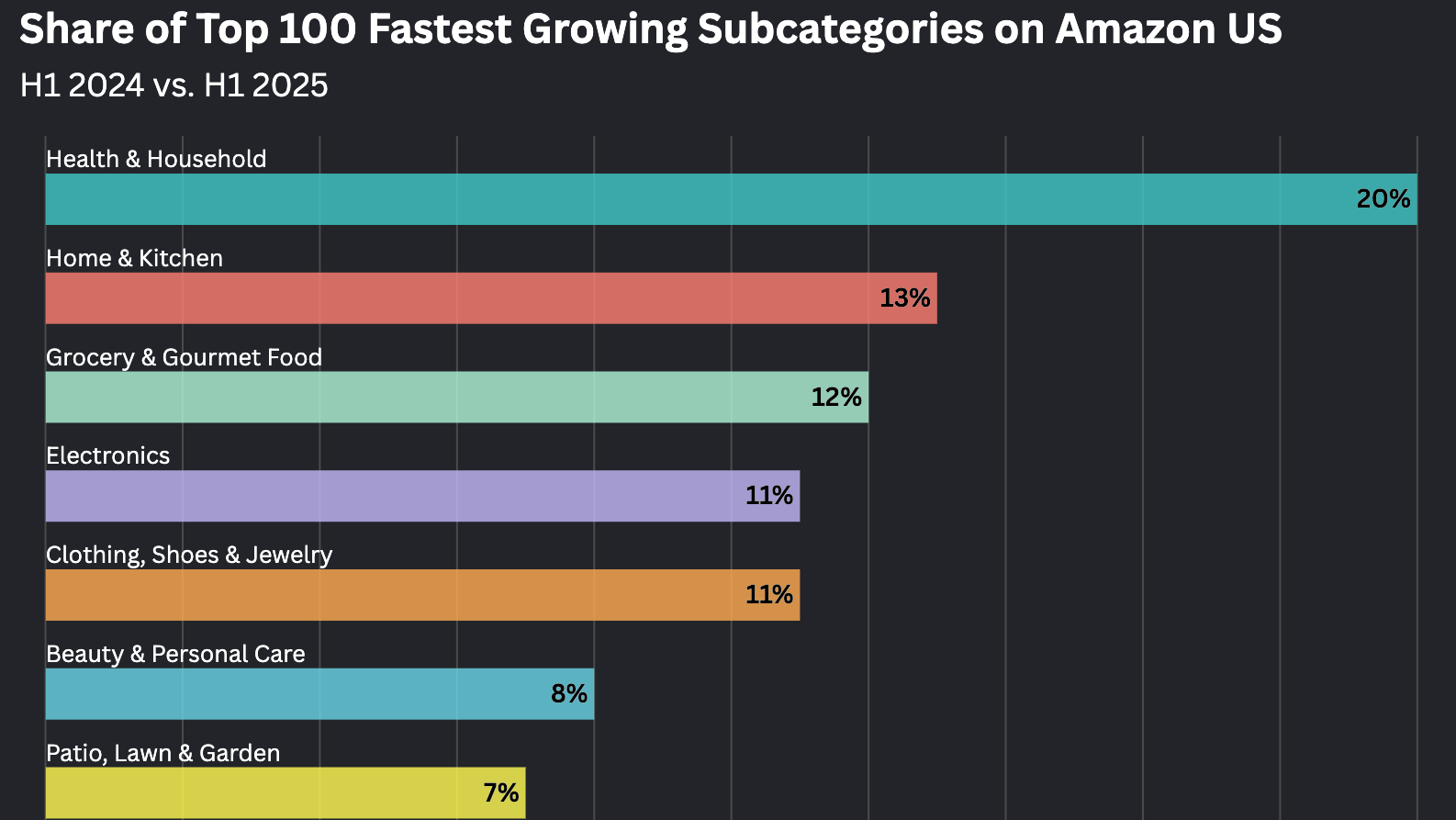
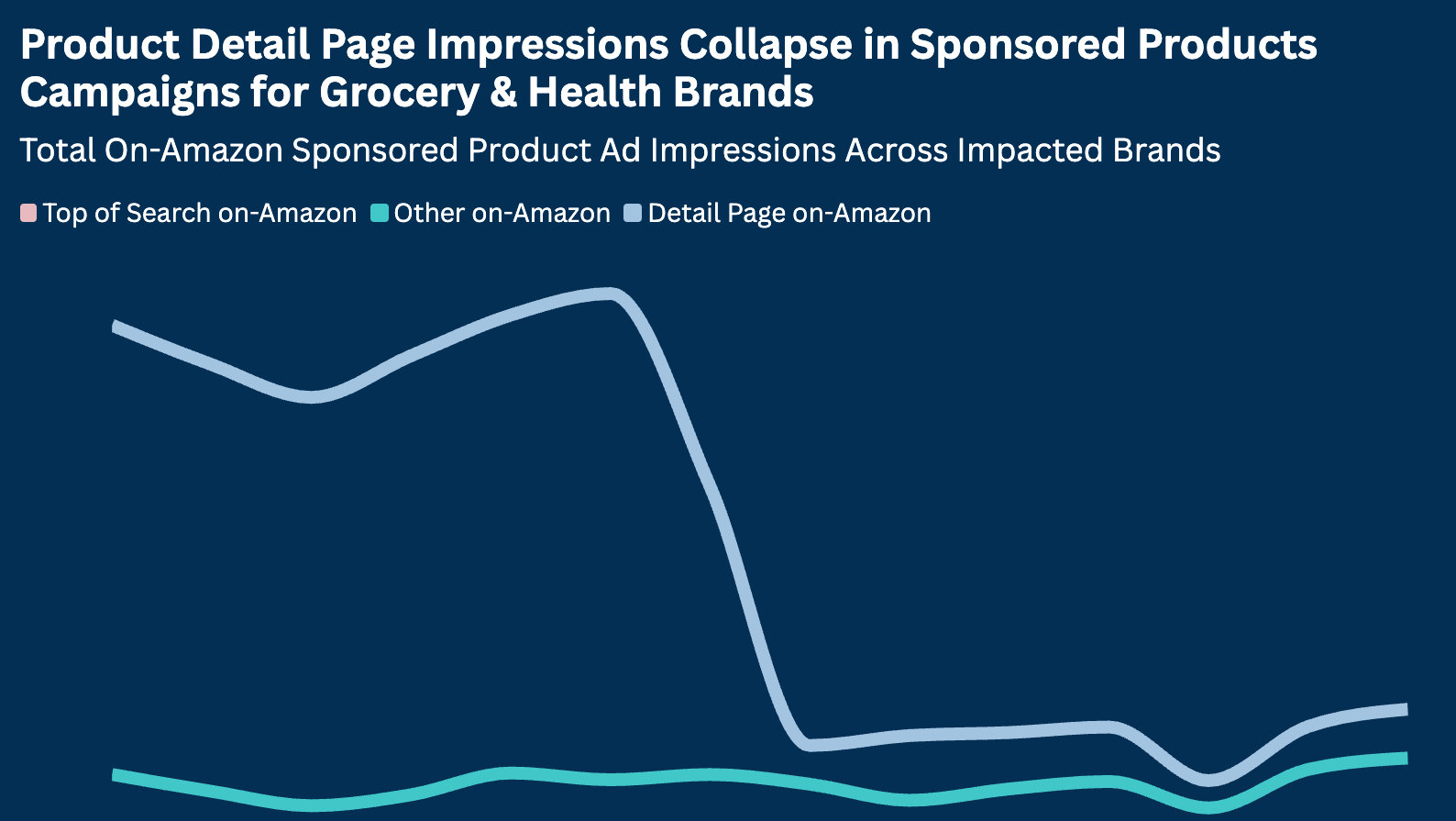
Relevance is how close a user’s search is to the keywords you associate with your product. Performance is how likely a user is to click on and then buy your product if it shows up as a result for a particular search query. But the marketplaces beneath these platforms are very dynamic – competitors move in and out, changing assortment, pricing, product content, logistical options, and advertising strategies to make their product sales fluctuate up and down. Furthermore, the platforms themselves experiment with various tactics to badge products for different reasons or merchandise variant products in different ways, and as a result your products’ rankings on different types of queries shift. These changes represent opportunities for you to tweak your own assortment, product content, pricing, fulfillment strategy, or advertisingIt is important to not only understand where your key products rank on your most important search terms, but also how those positions evolve over time for you and your competition.
In order to take advantage of these opportunities, you first need to detect them. That’s where marketplace visibility comes in. Much like we do here at Momentum Commerce, several SaaS platforms and data providers will enable you to see your product’s rank in the Search Engine Results Page for a variety of queries, including where your competitors rank. This data is useful, but also quite voluminous, making it difficult to find insights by hand on what could be thousands of queries across multiple products. To add to the complexity, your products’ positioning on these queries will likely have some natural volatility, and maybe even an underlying periodicity (maybe you rank better on the weekends or during working hours). How can we separate the wheat from the chaff, and detect only the cases that truly represent significant changes in the audiences that have high and low visibility to your products?
Statistical Anomaly Detection Techniques are Becoming Critical to Digital Retailing Success
Statistical anomaly detection algorithms and platforms can be quite helpful here. Below we explain one very simple method of performing this analysis to illustrate some of the concepts at play. The purpose of an anomaly detection system is to analyze time series data (which is a set of values over time), and determine if any of the points in that series are very unlikely to occur simply due to chance given what we know about the data, its characteristics, and its underlying volatility.
Here we can see an example time series. It has a few defining characteristics. First, we see that the values are consistently growing over time, which we often call the trend. Second, we see that the data has a natural pattern of fluctuation — a distinctive shape that repeats over and over. We call this a seasonal component, and time series data can have multiple seasonal components or none. However, if we look really closely at the point colored in red, it seems a little off. Even though some of the other surrounding points hit a level lower than the red labeled point, the red point seems out of place given the natural shape of the data.

It’s hard to see, and harder still to prove that this point is different enough to warrant attention. It’s definitely not something you’d notice unless you were really scrutinizing the data. To make these determinations easier to perform and more objective, some anomaly detection algorithms perform a Seasonal-Trend Decomposition. Remember how we discussed the concept of the underlying trend and seasonality of the above data? It turns out that we can use certain statistical methods to essentially subtract these components from the original time series, hence “decomposing” the time series into its seasonal part(s), its trend, and then anything left over. We can see this visually below.

Once we subtract the upward trend and that repeating seasonal pattern from the data, what’s left is called the residuals, or remainder (bottom chart in the stacked set of four above). Just glancing at these residuals, the red point appears much more out of whack, and it is far easier to identify as anomalous simply by eye. But, once again, there are more formal techniques and rule sets we can use here. One of the original and simplest rulesets for detecting anomalies actually stems from the world of manufacturing process control in the 1950s — from the Western Electric Company.
These famous rules, often called the WECO rules, state specific conditions and patterns that are quite unlikely to occur due to chance in a time series. One of them (WECO Rule 4), which I consider the easiest to understand, simply talks about consecutive points above or below the mean of a time series. Since any point has a 50/50 chance of being above or below the mean, if we get 9 points in a row on the same side of the mean (either above or below), the probability of that occurring due to chance is 0.59, which equates to less than 0.2%. This is an extremely small probability, and so it is much more likely that if you observe 9 consecutive points above or below the mean of a time series, it’s because something actually meaningfully changed, and therefore warrants attention.
For the above time series of residuals, WECO Rule 1 would likely indict the red point as anomalous, which states that any point outside of 3 standard deviations from the mean of a time series is likely an anomaly. or a normally distributed data set, we’d expect 99.7% of points to fall within 3 standard deviations of the mean, meaning a point outside would only occur due to chance roughly 0.3% of the time. Now, this leads to the question of: what should our threshold be to indict a point as anomalous in terms of probability to occur due to chance? That is a big question and one we’ll save for another article!
Hopefully, this simple introduction to time series anomaly detection can illustrate the utility and power of leveraging even basic statistical methods to extract the key insights from vast swaths of time series data. Now, in more modern anomaly detection algorithms, the techniques and rulesets deployed are far more sophisticated (though using WECO rules on seasonality-trend decomposed data will actually get you pretty far!), but the general concepts still hold. As a seller, the faster and more accurately you can find key shifts in your performance, the better you can adapt your product offerings, pricing, and creatives to ensure you maximize your performance in the ever-changing market landscape dictated by the digital retail algorithms.
The Momentum Commerce Data Observatory and Our Journey Ahead
Stay tuned to the Momentum Commerce blog “The Next Frontier” as we share the lessons we learn in applying some of these techniques to the sales and marketing strategies of our client partners.